-
 数据分析平台
数据分析平台
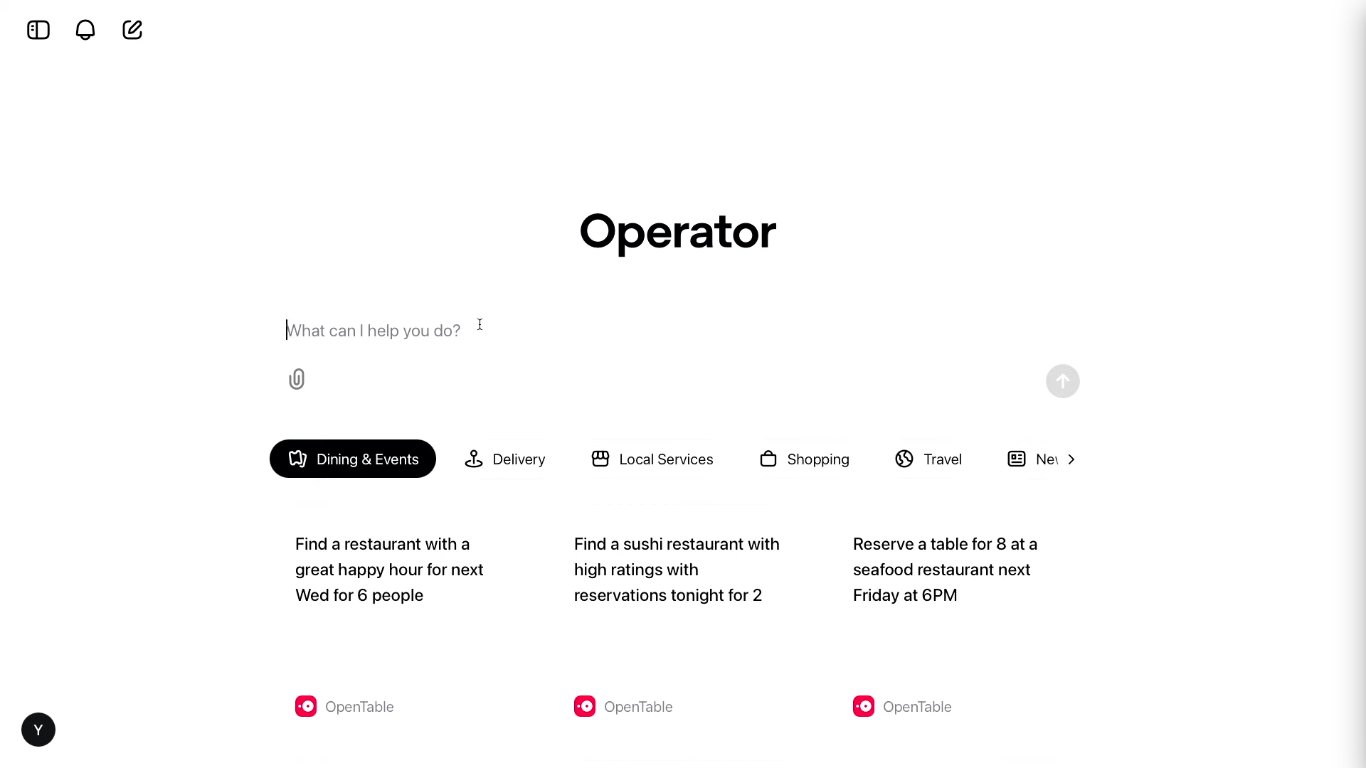
【伦敦】数据分析平台Fluent获得690万欧元种子轮融资,以实现其AI驱动的数据分析仪横扫整个工作量的目标
改变决策者获取和使用商业数据方式的数据分析平台 Fluent 宣布完成由 Hoxton Ventures 和 Tiferes Ventures 领投的 690 万欧元种子轮投资。新投资将用于加速 Fluent 突破性技术的开发,并扩大其在欧洲的人工智能和机器学习专家团队。
Fluent 公司成立于 2021 年,是一家由人工智能驱动的数据分析师公司,它能让非技术团队成员用简单的英语直接向数据提出问题,在几秒钟内获得洞察力,并让数据团队免于手动回答临时数据请求的痛苦。
Fluent 公司首席执行官Robert Van Den Bergh说: "数据团队平均有 40% 的时间用于回答来自业务部门的问题。对数据团队来说,这些问题很多都很容易回答,但却使他们无法进行更深入、更具战略性的分析,而这些分析可能会改变他们的业务。借助 Fluent 的自然语言界面,我们可以帮助团队成员自助回答他们的数据问题。
在过去两年中,Fluent 赢得了包括贝恩公司在内的旗舰客户,实现了数据访问的民主化。
贝恩公司合伙人Ian Weber评论说: "Fluent 的平台帮助我们利用 LLMs 对大型复杂数据集进行分析并提供见解。Fluent 允许我们的非技术用户快速、高效、准确地获得所需的答案,尤其是对于预建数据仪表盘而言过于复杂或具体的问题。我们很高兴能探索 Fluent 未来如何帮助我们的客户更好地获取数据和见解。
Fluent 首席技术官Cameron Whitehead补充说:"我们的客户已经采用了 Tableau 和 Looker 等商业智能工具,希望他们的非技术团队成员能够自行查询数据,但很快就发现这些工具技术性太强,导致只有一小部分团队成员真正使用它们。Fluent 就是为了满足那些非数据专家的团队成员的需求而打造的。
自2022年OpenAI的ChatGPT推出以来,各组织一直在对该技术进行测试,以了解在哪些方面可以提高工作效率,而分析Excel文件一直是比较受欢迎的应用之一。然而,能够与组织一起扩展的企业就绪解决方案仍处于萌芽阶段,准确性和信任度方面的担忧限制了该技术的采用。Fluent 弥补了这一缺陷,提供了一个企业就绪的解决方案,让数据团队可以轻松地整理、管理和信任数据。
Hoxton Ventures 合伙人 Charles Seely 评论说: "在一个数据驱动的世界里,目前的数据分析方法是企业的短板,在他们的组织中造成了永久性的瓶颈,拖慢了每个人的速度,阻碍了决策。Fluent 的方法不仅具有创新性,而且是企业迫切需要的,我们很高兴能参与他们重塑企业与数据交互方式的旅程。
Tiferes Ventures管理合伙人、InVision联合创始人Clark Valberg补充说:"Fluent通过在每个组织层级实现实时访问数据驱动的洞察力的民主化,实现了协作智能的全新模式。我相信这是现代企业内部发生的最重要的战略和文化演变。
-
 数据分析平台
数据分析平台
某家公司有哪些关联人、发生了哪些事,这个高级版的搜索引擎为你“人肉”企业情报
风报是一家面向企业,基于公开信息的企业情报分析及风控系统,在风报的搜索引擎上输入人名、公司名称等,可以快速获得所有的关联信息,包括企业投资过哪些企业,以及相关股东(包括二级股东)、甚至这家公司可以和哪家公司进行财产转移,都会以简单明了的形式呈现。2015年9月正式发布以来,风报已拥有500多家企业用户。
记者了解到,风报已完成数千万级的 Pre-A 轮融资。
在公开数据中搜集信息
风报联合创始人兼CTO闵可锐说,风报相当于一个垂直行业的百度,不仅罗列了企业信息,还做了结构化的梳理,将信息自动整理和归类,通过信息量来确定关联程度,并把数据图形化。
风报通过对司法文书的语义分析,形成完整的关联图,挖掘更多关联背后的真相
此外,风报还可以对企业性质进行判断,比如是否具有风险信号,是否曾为失信被执行人,是否存在刚刚立案的官司,税务是否正常缴纳等。这些信息还可以通过绑定微信直接推送给用户。
闵可锐对创业邦说,目前风报最早可以检索到2003年的信息,并且以小时来进行更新,新增的数据量每天在2000万左右。
而风报的数据来源主要分为两个方面:
1. 偏政府的信息,包括行政信息、司法信息、工商信息、专利登记信息等。例如开庭公告、裁判文书,审判结果执行情况等。目前,风报覆盖了12000家政府类网站。
2. 偏媒体的公开信息。风报把过去14年的20亿条经营类事件分为23类,捕捉对企业情报、风险有特定指向的事件,如高管变动、员工情况、是否有项目破产或暂停、是否有大股东增持或减持、业务上是否有变动等等。
从语义数据分析平台衍生而来
事实上,风报是在“玻森数据”的基础之上开发的一款产品,后者也是风报的技术核心。风报的创始人兼 CEO 李臻说,作为连续创业者的他,很看好人工智能这个方向,而中文文本处理及语义分析是人工智能很重要的一个方面,因此2012年7月,他成立了开发自然语义引擎处理平台的玻森数据,第三方公司可以利用这项一平台进行数据分析场景和产品应用场景的开发。
目前玻森数据上注册了4000位开发者和用户,分别为科技公司的开发者、研究咨询公司的数据分析部门、社交媒体的监测分析公司、舆情公司的引擎分析部门、品牌商的客户分析部分等。
总体来说,玻森数据可以实现以下几个方面的分析:
1.分词和词性的标注。
中文没有明确的词的定义,词与词之间没有区分符,这是中文处理首先会遇到的一个挑战,因此,玻森通过机器为词语加上分隔,并匹配相对应的词性。
2.实体的识别,也就是具体的产品、地点、时间、职位等名词。
闵可锐说,之所以能在这么短的时间内把这些词提取出来,绝不是玻森有所有词的名单列表,而是通过更长的上下文来决定词性,这也是和传统的关键词匹配方法和语义分析方法较大的区别。
3.文法分析,让机器去理解文章的结构。
4.情感分析,基于实体级别及语义的正负面程度分析。
在美国,与玻森类似提供语义分析引擎的公司AlchemyAPI在2015年被IBM收购,作为IBM Waston体系的布局,只是前者处理的是英文,而风报提供中文的处理分析。李臻说,中国在自然语言处理引擎的使用跟美国有较大差异,美国有很多的二次开发者和商业模式的开发者,但中国更看重结果的分析。这几年来,他们也一直在寻找一条更好的变现途径,恰逢中国开始推行政府公开化,同时,媒体信息也以几何倍的数量增长。因此,2015年,他们在玻森NLP(Natural Language Processing 自然语言处理系统)的基础上设计了自己的产品,就是风报。
未来会开发更多功能
目前,也有一些具有类似功能的产品。但李臻说,基于玻森数据在NLP技术上的优势,风报在数据种类及深入分析上更为全面。
下图为玻森曾做的自然语言处理系统在分词引擎上的测评结果:
创业邦了解到,风报根据客户查询和关注的公司数量进行收费,通常会根据企业全年需要关注的企业数量给出定价。
李臻说,未来风报将不断扩充数据源和数据分析功能,尤其是在专业性上。在服务某些特定行业,数据和功能可以形成某些行业特点,因此,针对某些专业领域的数据分析,风报会开发更多的功能。
也就是说,风报可能会衍生出有功能特性的版本,比如,根据行业对功能和特性做出调整。但李臻也说,目前最重要的还是把通用的功能做完整。
同时,风报也会使查询方式更为便捷,无论输入公司、产品、人都会找到关联企业。
来源:创业邦 作者:杨绚然
如果你或你的朋友的项目希望被 HRTechChina报道,戳这里可进行寻求报道。
HRTechChina提供、关注最尖端的人力资源科技资讯。您可以搜索“HRTechChina”公众号或扫描以下二维码关注我们!
 扫一扫 加微信
hrtechchina
扫一扫 加微信
hrtechchina