-
 Turnover Models
Turnover Models
人员分析:在人员流动模型中建立可解释性
文/Ridwan Ismeer
最近,我有幸与来自新加坡理工大学的一群才华横溢的学生一起工作。他们的任务是帮助构建一个非常普通的人员分析应用程序:预测员工流动率(此类应用程序的优点、相关性和伦理值得商榷,可以单独讨论)。
摘要:建立一个能够准确预测员工情绪的模型,在0-6个月,6-12个月和>12个月的时间范围内的周转风险。
这两项不可谈判的要求是:
1.准确性:真阳性高,假阳性低。大多数实践者会强调低假阴性,但我们有理由不这么做。
2.可解释性:在人员分析中,模型的可解释性是采用模型的关键。人员分析的最终用户通常想要理解为什么模型要预测它是什么。事实上,GDPR有新的规定要求人工智能的决定是可解释的。
现在,任何分析实践者都可以很快地指出,这两个需求之间存在一个内在的平衡。精确的模型很少是可解释的。可解释的模型很少是准确的。但我们想检验这个假设的二分法。因为在人员分析中,仅仅精确是不够的——它需要用户能够理解。
除了我们两个严格的要求外,我们还为团队提供了一个强大的人力资源指标列表、一个足够大的数据集以及评估以下算法所需的基础设施:
和往常一样,xgboost在预测营业额方面表现最好(引用Kaggle上最常用的算法之一)。事实上,它的TP和FP速率满足了我们对精度的要求。容易解释的模型,如GLM和逻辑回归只是没有比较。
然而,任何以前使用过这个算法的人都可以证明,要想弄清楚它的黑盒子里发生了什么是多么困难。我们可以告诉股东鲍勃的离职风险很高,但我们无法解释原因。
或者我们可以吗?
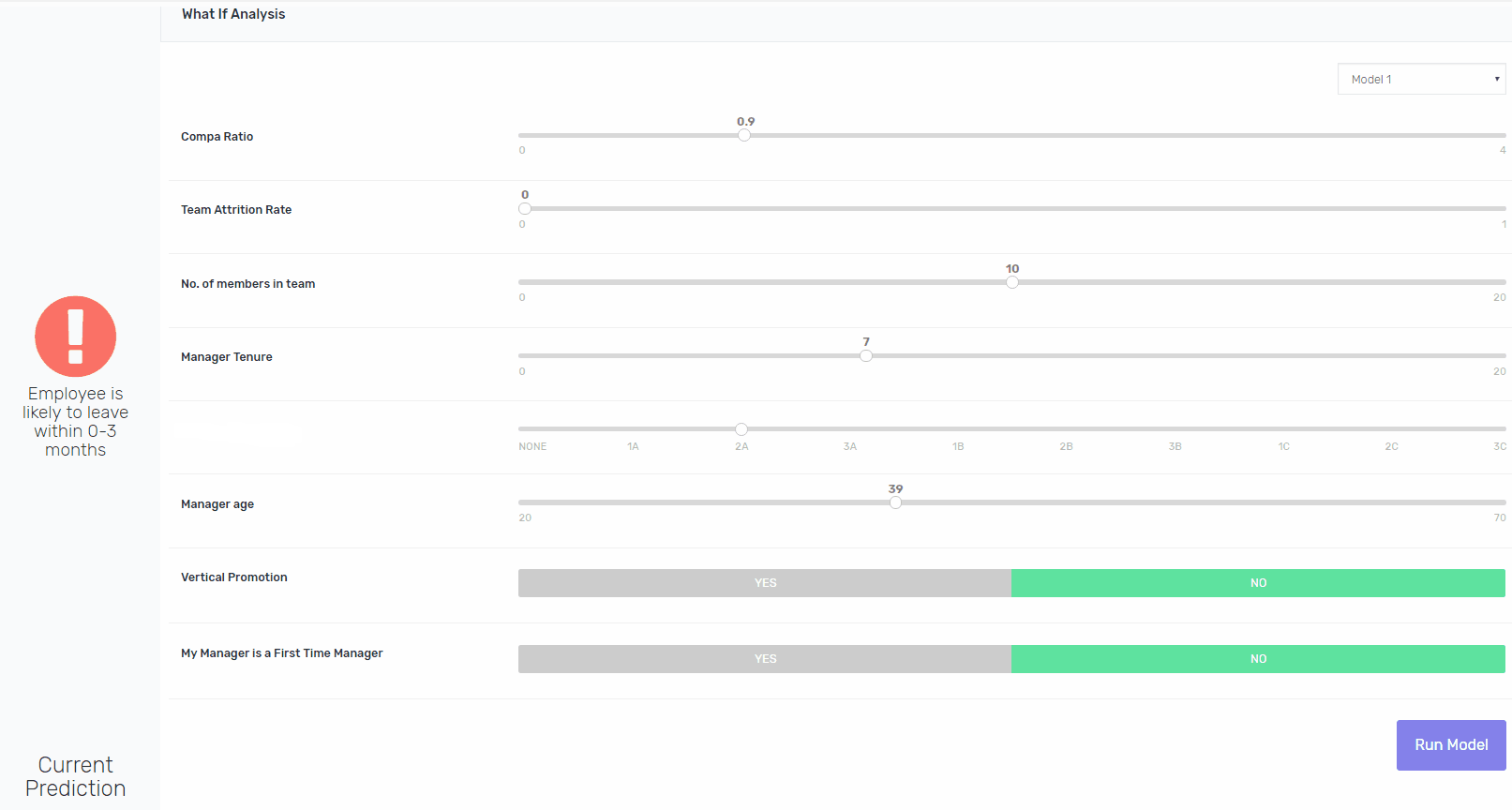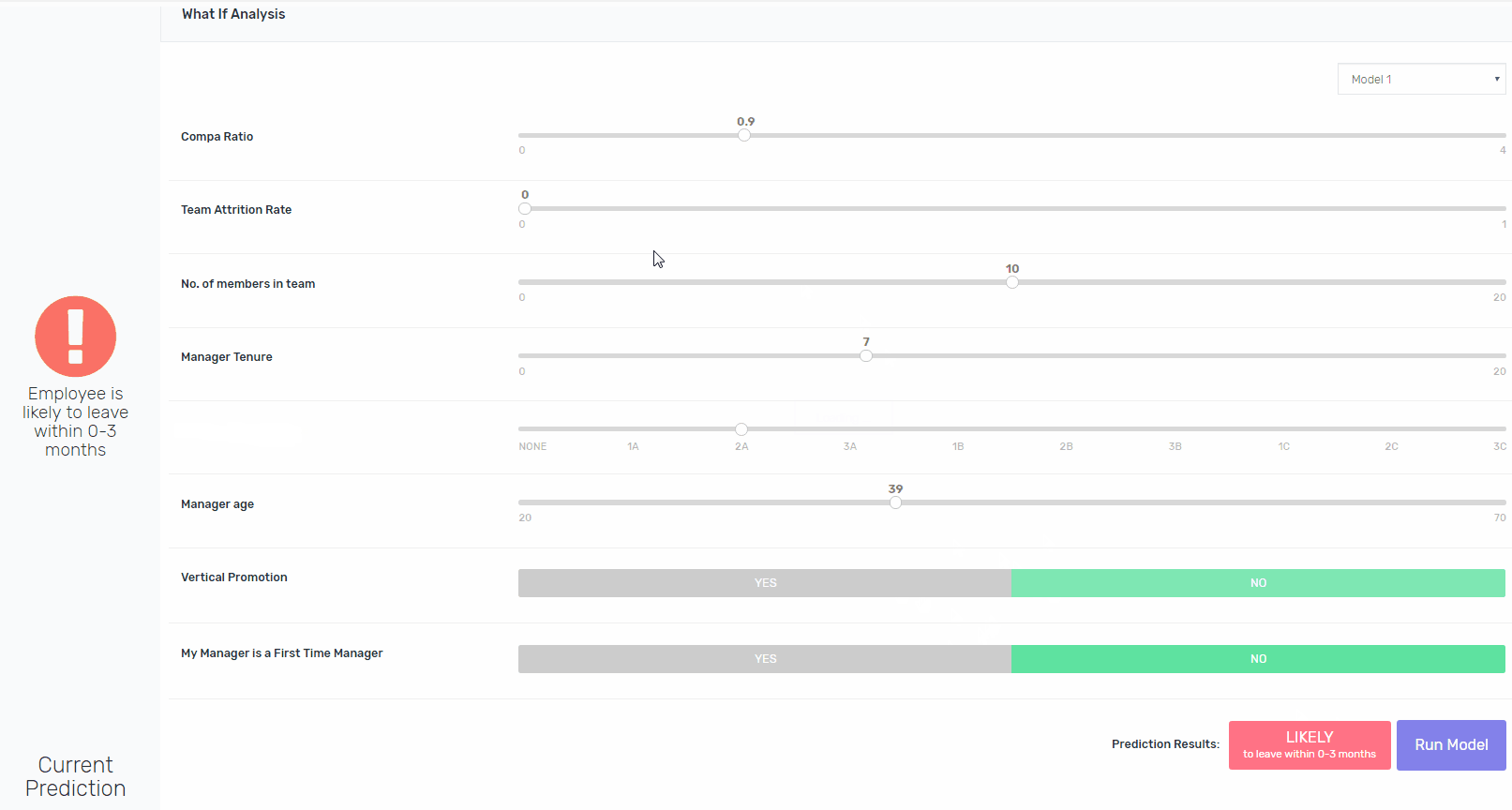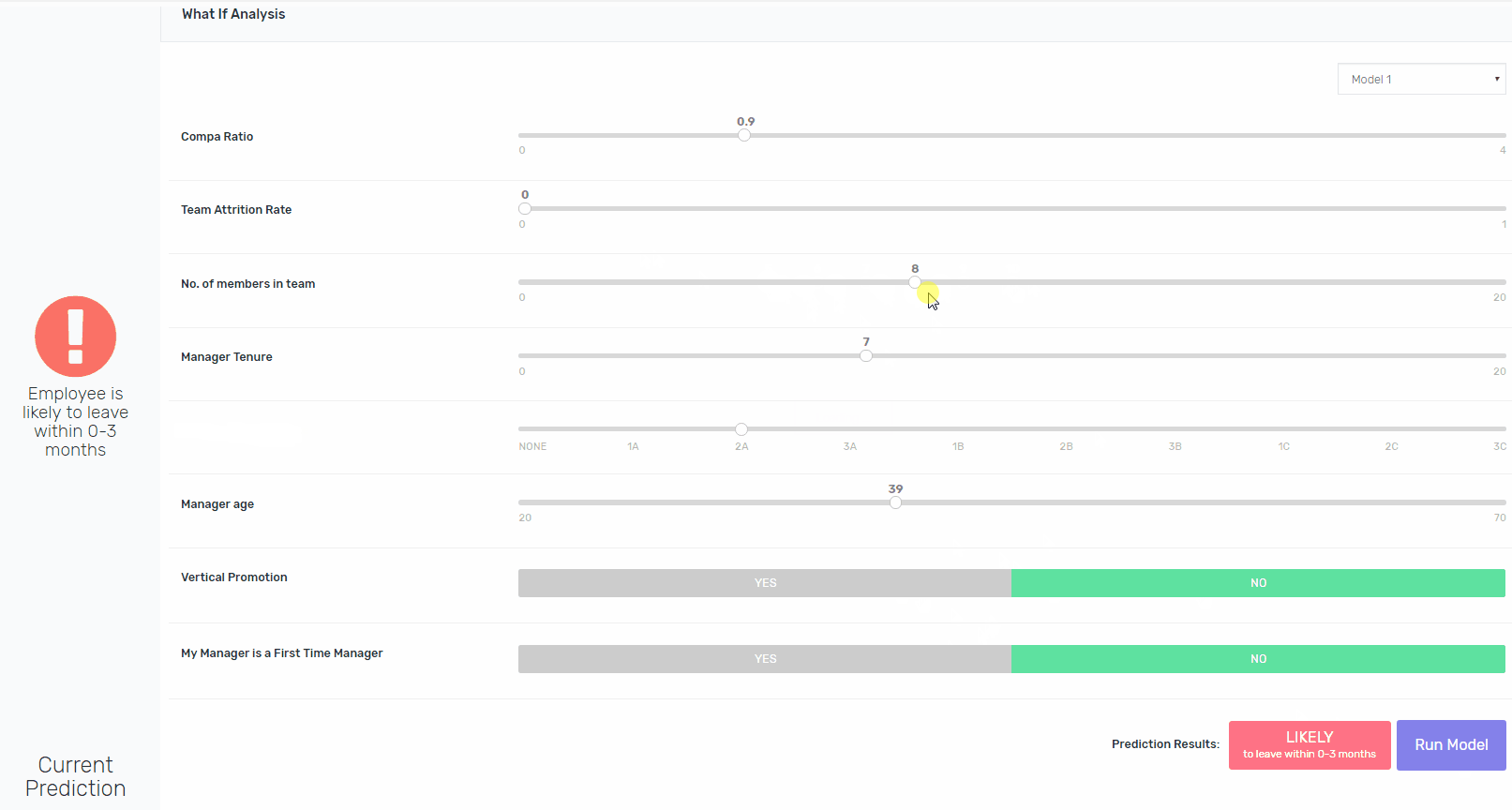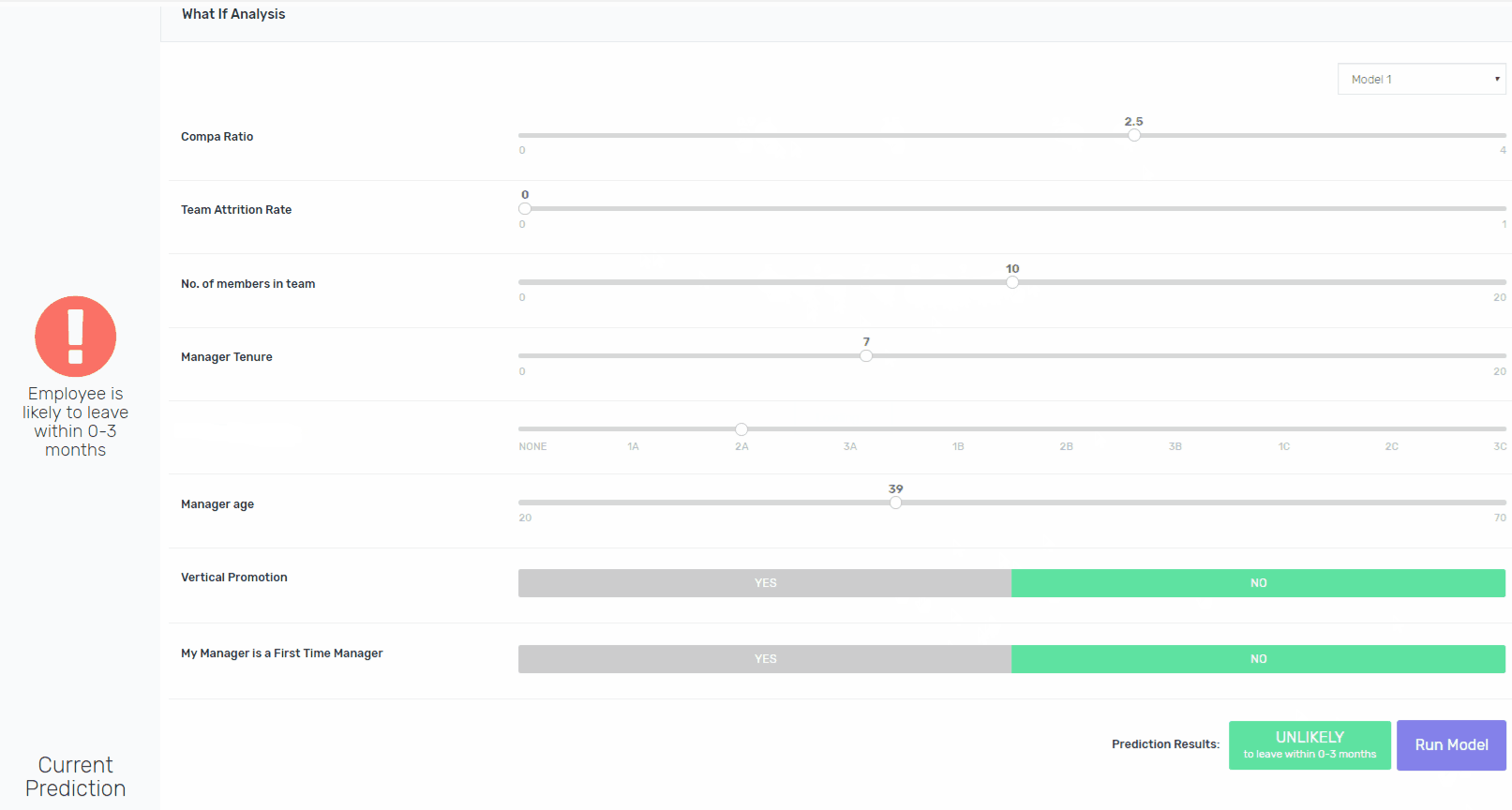
将可解释性构建到像XGBoost这样的算法中并非易事,但这是可能的。除了向涉众提供处于风险中的员工的姓名之外,我们还为他们提供了一个交互平台,用于修改现有的功能,并重新运行模型,以指向导致模型将其评为处于风险中的功能。如果鲍勃去年升职了,模特会得出同样的结论吗?是的,它将。如果Bob在一个较小的团队中,模型会得出相同的结论吗?是的,它将。如果他的工资比市场上的要高呢?不。瞧。
由于用户需要进行多次迭代才能更好地理解每个案例,因此需要进行大量的工作,但是它允许我们保持较高的准确性,同时为涉众提供必要的模型内部工作,以使其更易于解释。
一些免责声明:
1.本帖旨在解决可解释性和准确性之间的错误二分法,而不是鼓励使用个人离职模型。事实上,我甚至会说,诸如加薪和提供晋升等行动绝不应以离职风险为基础。这对精英文化来说可能是灾难性的。对一般离职动因的综合分析应该是离职模型所能做到的。
2.首先,关于可解释性的必要性有很多争论。埃尔德研究中心的约翰·埃尔德博士认为,人类过于依赖基于先前经验的确认偏差,无论如何都无法客观地解释模型的结果。辩论还在继续。点击这里了解更多内容。
3.图像中使用的数据完全是基于虚假数据,仅用于说明方法。
4.我有自己的看法。
以上为AI翻译,内容仅供参考。
原文链接:People Analytics: Building for Interpretability in Turnover Models
Turnover Models
2018年11月30日
 扫一扫 加微信
hrtechchina
扫一扫 加微信
hrtechchina





